|
Lei Chen(陈 磊)
I'm currently a Assistant Researchor of Department of Automation, Tsinghua University, China. Before that, I was an Associate Professor with the School of Computer and Communication Engineering, University of Science and Technology Beijing, China (Nov. 2022 to Jan. 2024). And I was a postdoctoral researcher of Department of Automation, Tsinghua University, China (Jun. 2020 to Oct. 2022). My current research interests lie in computer vision and pattern recognition.
|

|
Recent Selected Publications(*Equal Contribution, #Corresponding Author) |
|
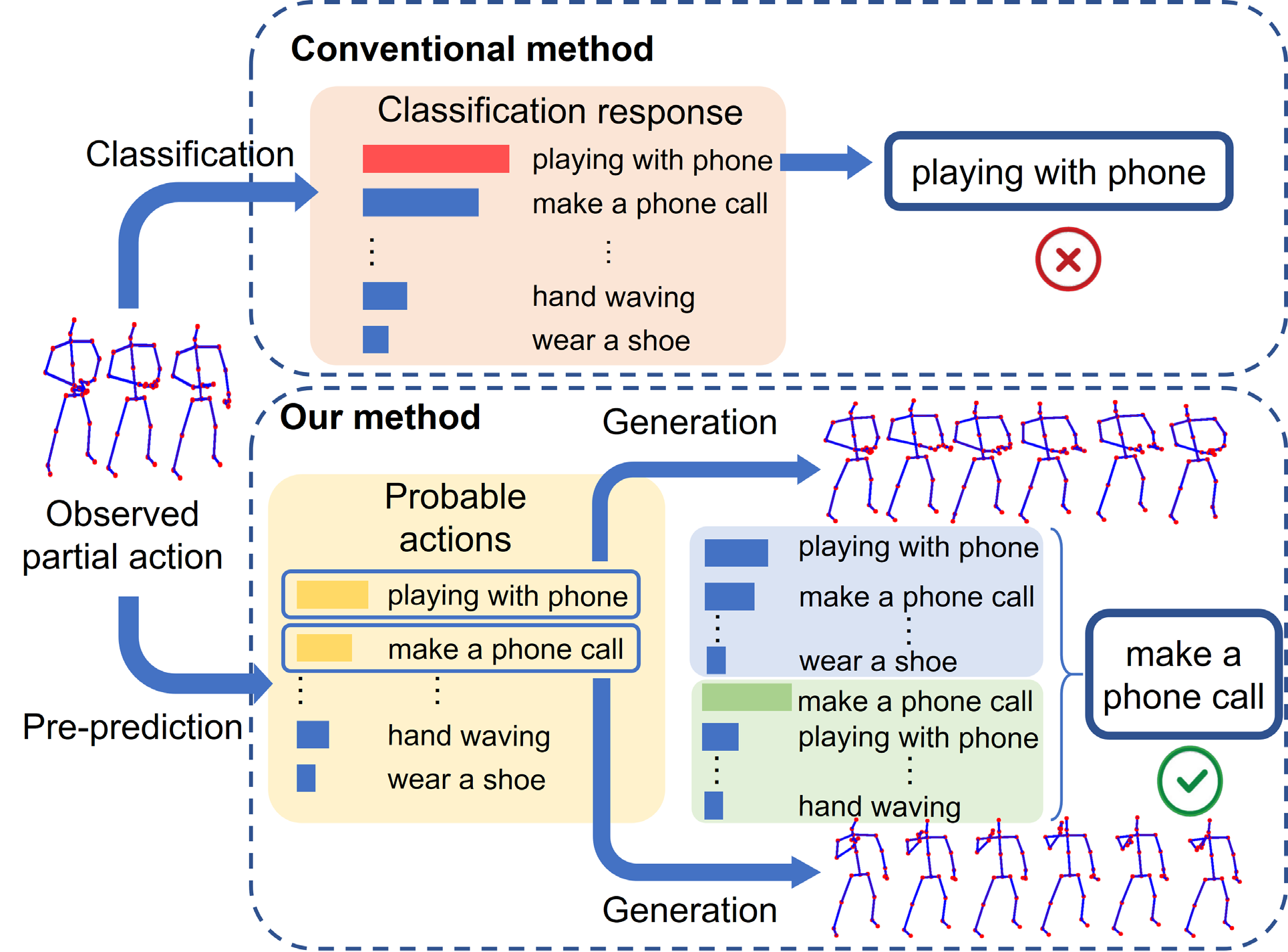
Ambiguousness-Aware State Evolution for Action Prediction
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2022. We propose an ambiguousness-aware state evolution (AASE) method which represents the uncertainty of the input sequence and evolves the subsequent skeletons to generate a reasonable full-length sequence for action prediction. |
|
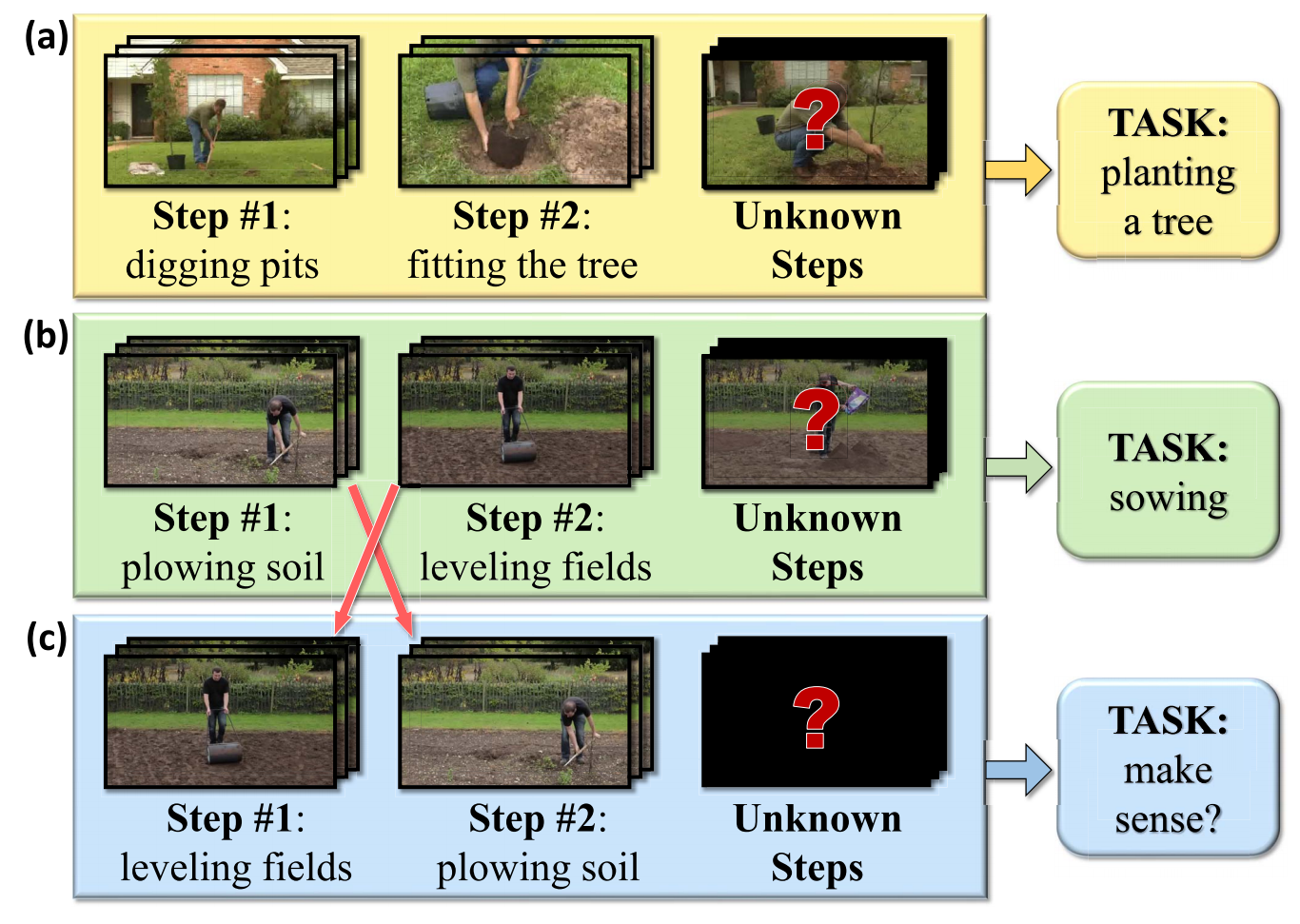
Order-Constrained Representation Learning for Instructional Video Prediction
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2022. We propose a weakly-supervised approach called Order-Constrained Representation Learn-ing (OCRL) to predict future actions from instructional videos by observing incomplete steps of actions. |
|
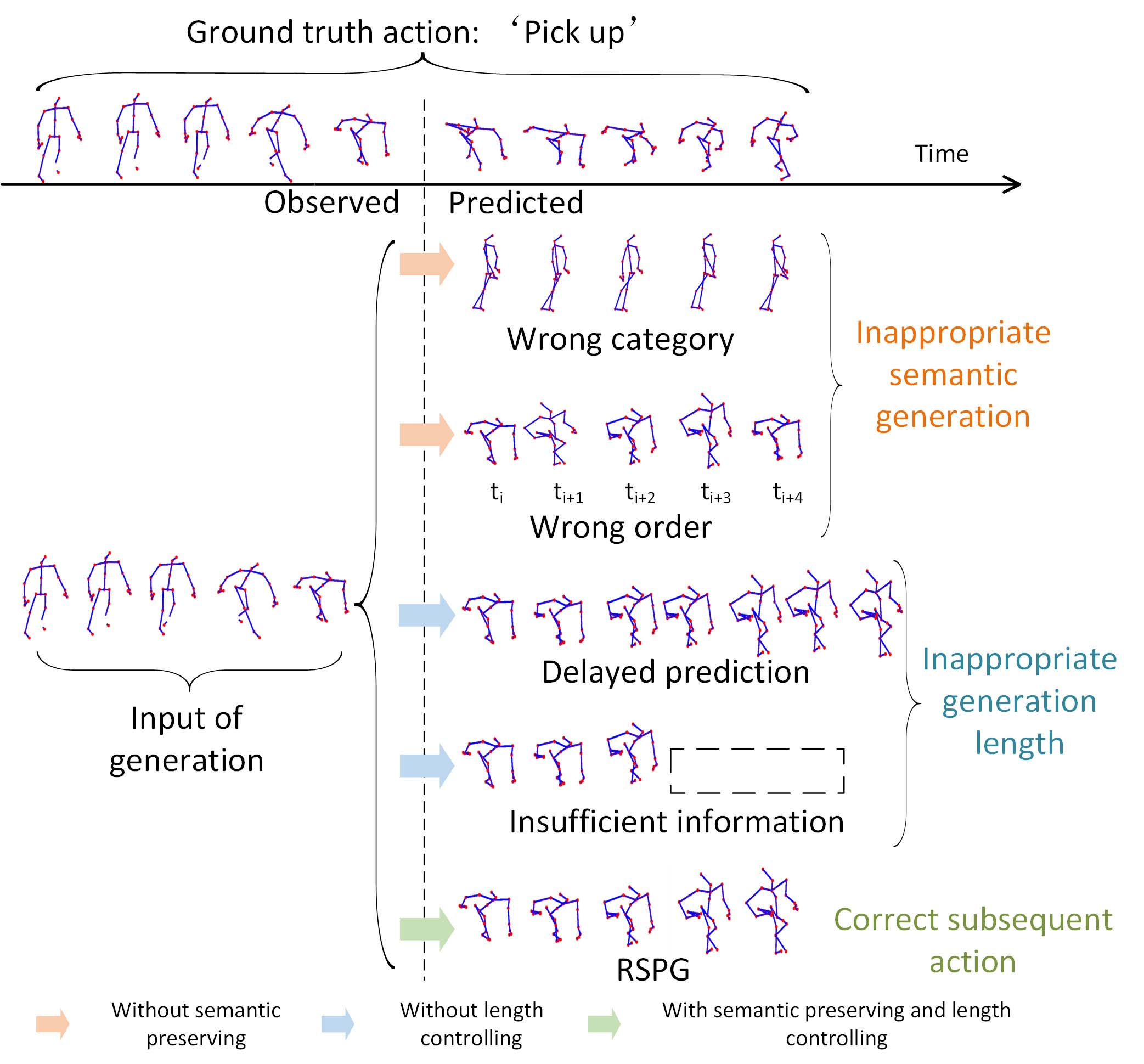
Recurrent Semantic Preserving Generation for Action Prediction
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2021. We propose a recurrent semantic preserving generation (RSPG) method for action prediction. Our method learns to capture the tendency of observed sequences and complement the subsequent action with adversarial learning under some constrains, which preserves the consistency between the generation sequence and the observed sequence. |
|
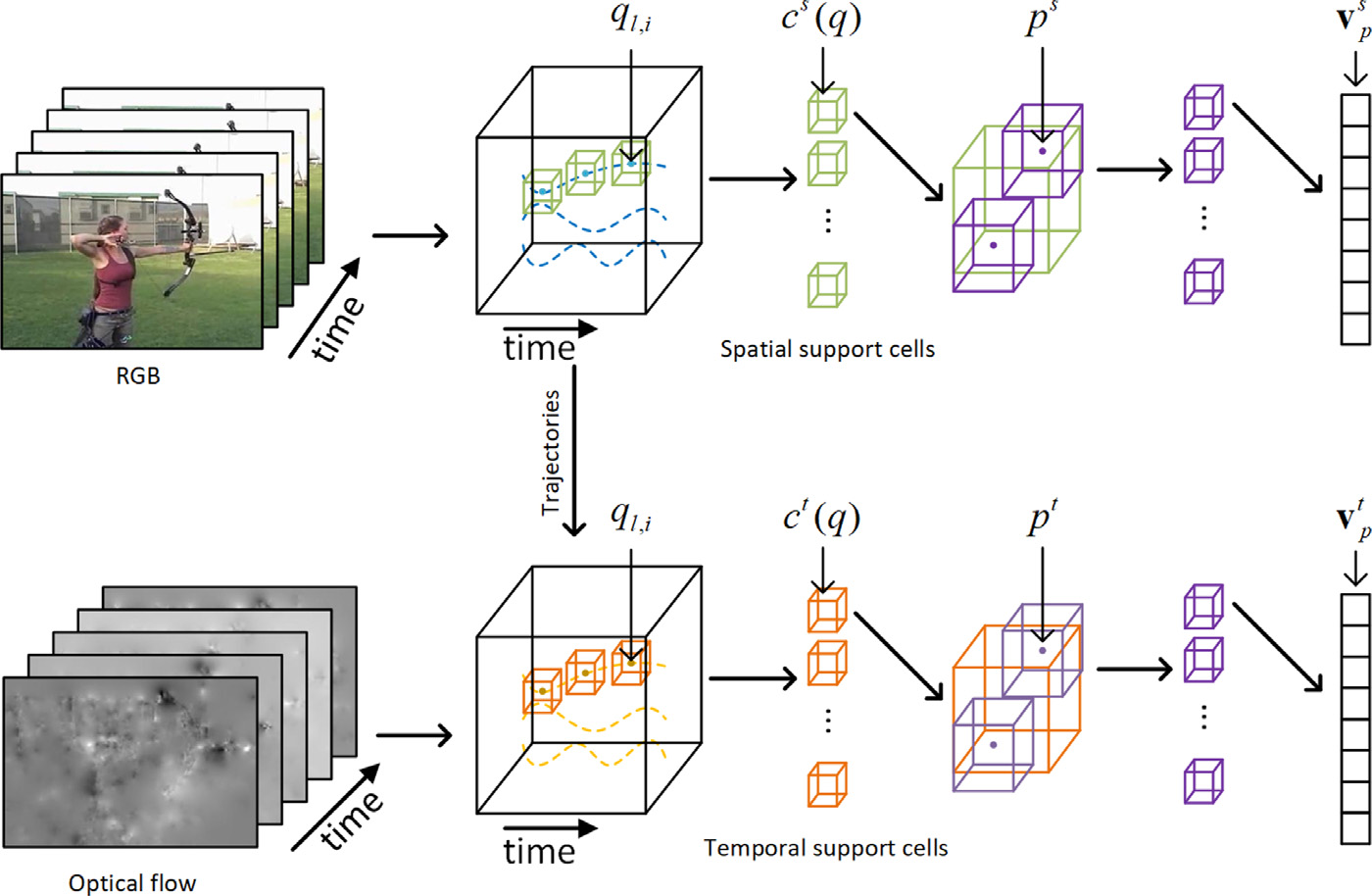
Learning Principal Orientations and Residual Descriptor for Action Recognition
Pattern Recognition (PR), 2019. We propose an unsupervised representation method to learn principal orientations and residual descriptor (PORD) for action recognition. Our PORD aims to learn the statistic principal orientations and to represent the local features of action videos with residual values. |
|
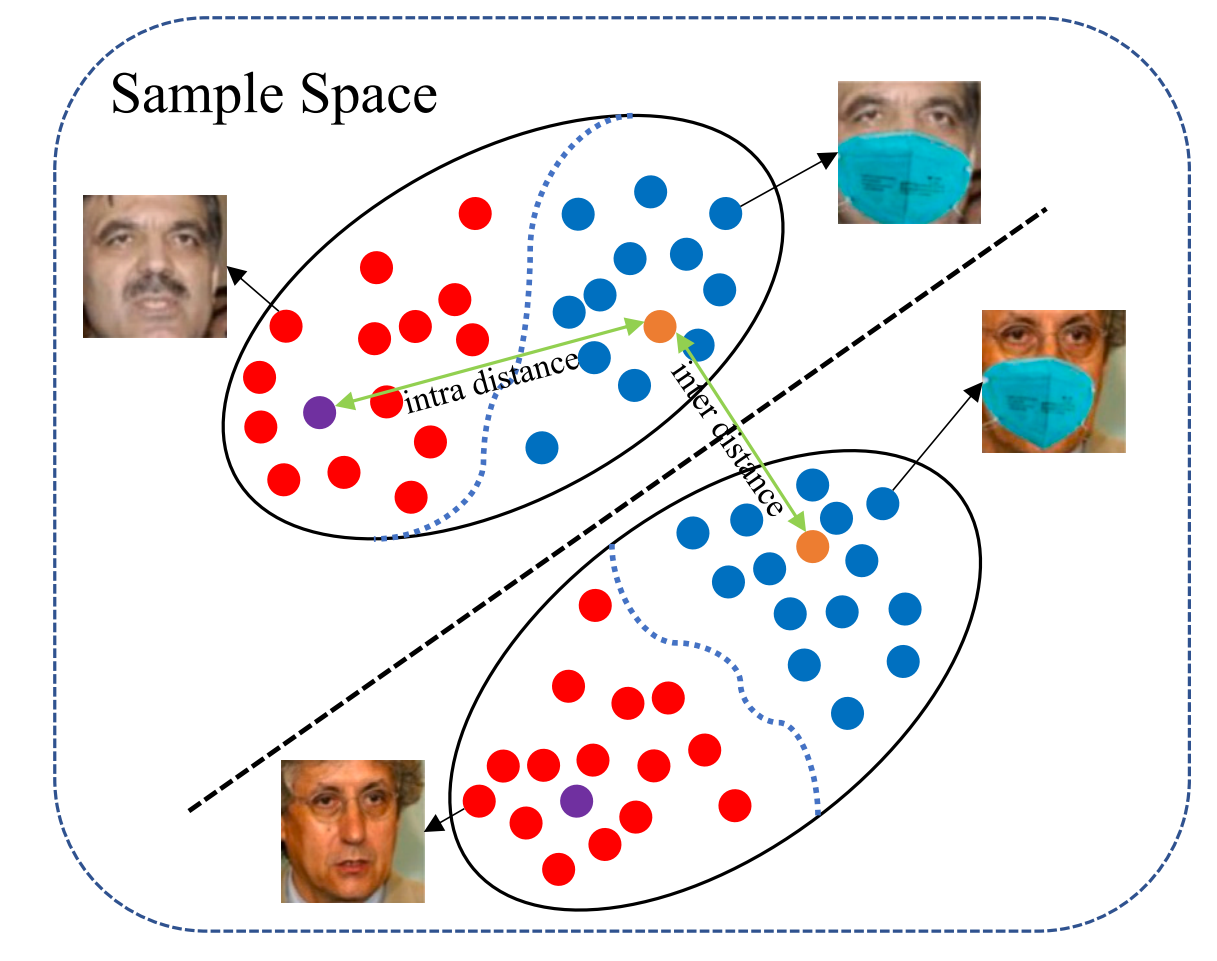
Hypersphere Guided Embedding for Masked Face Recognition
Pattern Recognition Letters (PRL), 2023. We propose a framework to enable existing methods to accommodate multiple data distributions by orthogonal subspaces. We introduce constraints on multiple hypersphere manifolds via MultiCenter Loss and employ a Spatial Split Strategy to ensure the orthogonality of base vectors associated with different hypersphere manifolds, corresponding to distinct distribution. |
|
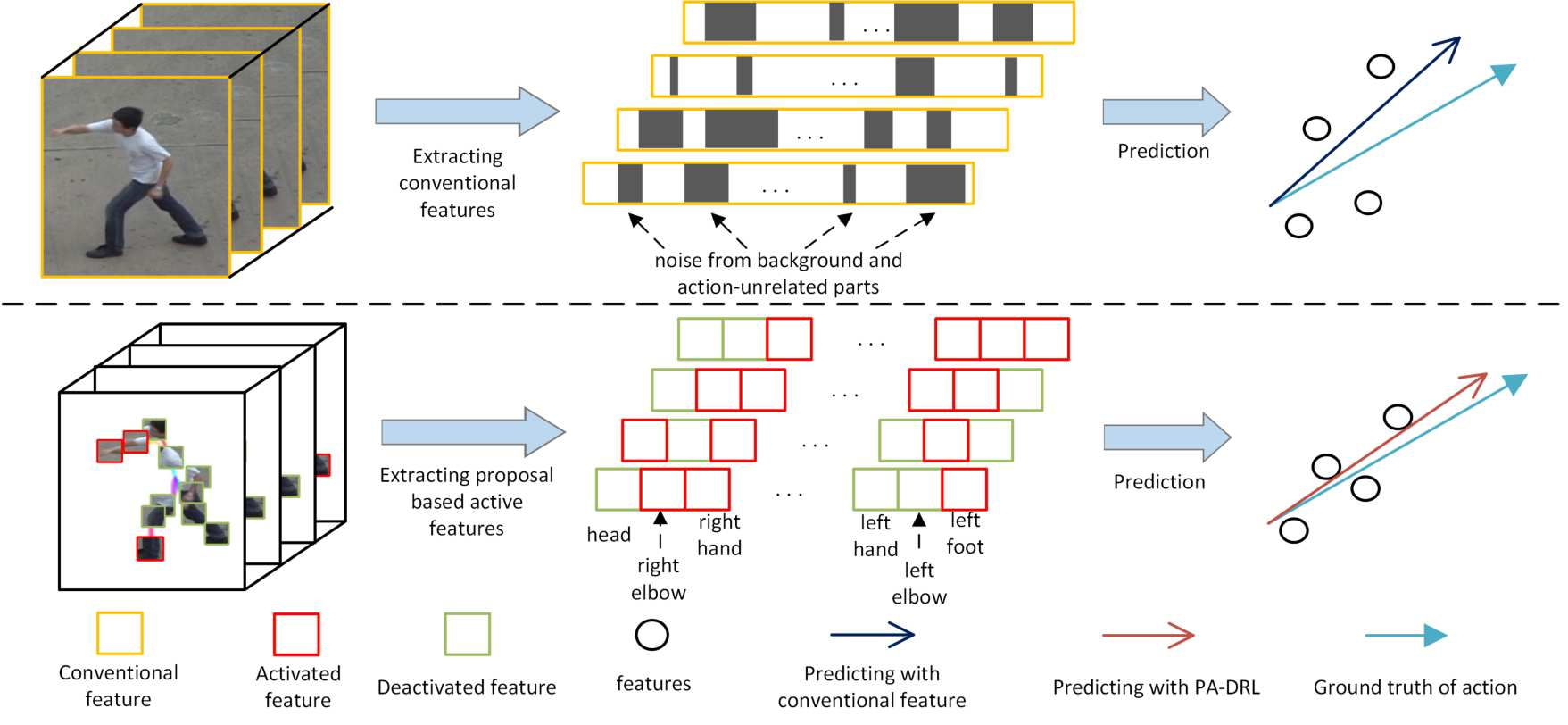
Part-Activated Deep Reinforcement Learning for Action Prediction
European Conference on Computer Vision (ECCV), 2018. We propose a part-activated deep reinforcement learning (PA-DRL) method for action prediction. We design the PA-DRL to exploit the structure of the human body by extracting skeleton proposals under a deep reinforcement learning framework. |
|
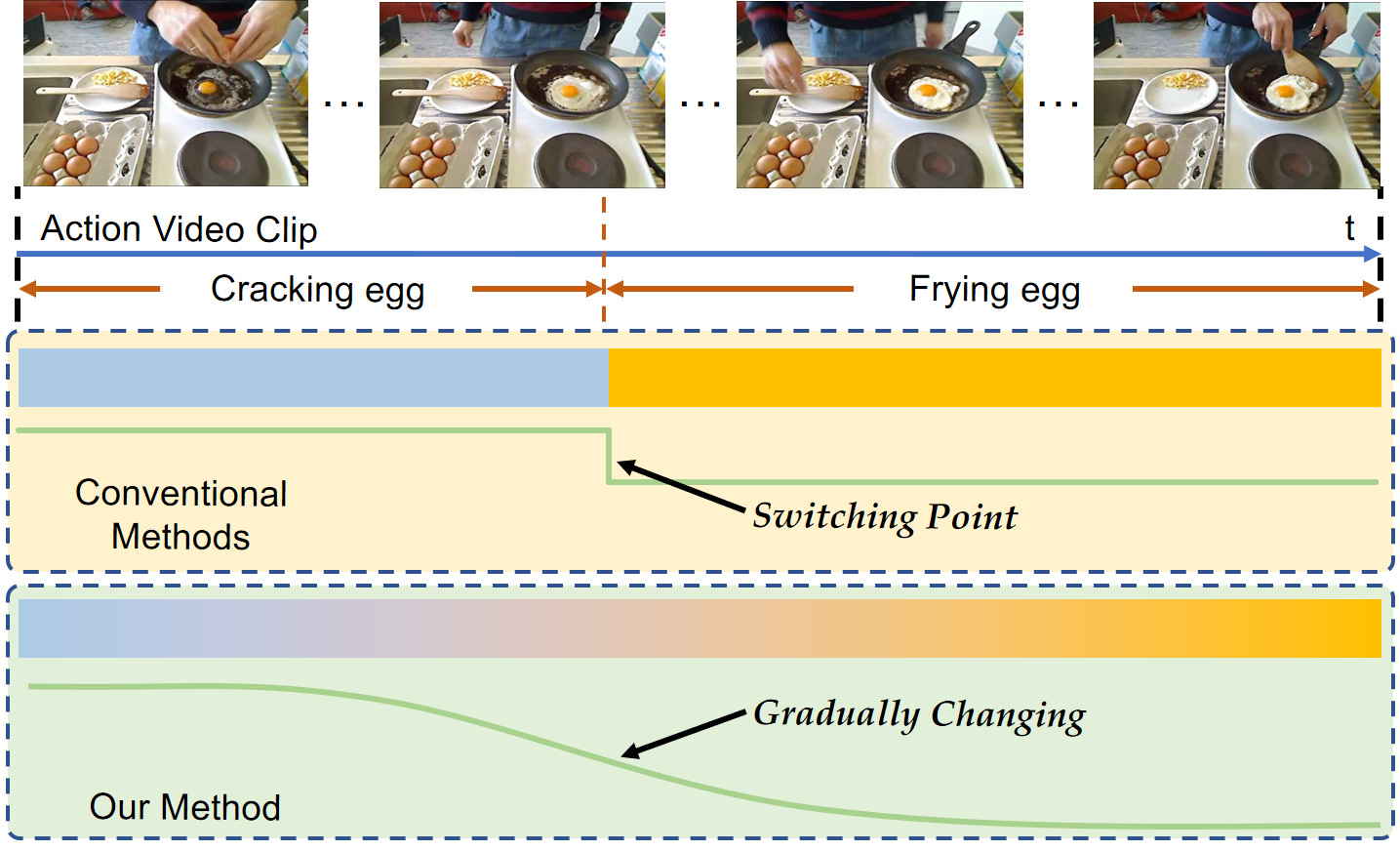
Uncertainty-Aware Representation Learning for Action Segmentation
International Joint Conference on Artificial Intelligence (IJCAI), 2022. We propose an uncertainty-aware representation Learning (UARL) method for action segmentation. we design the UARL to exploit the transitional expression between two action periods by uncertainty learning. |
|
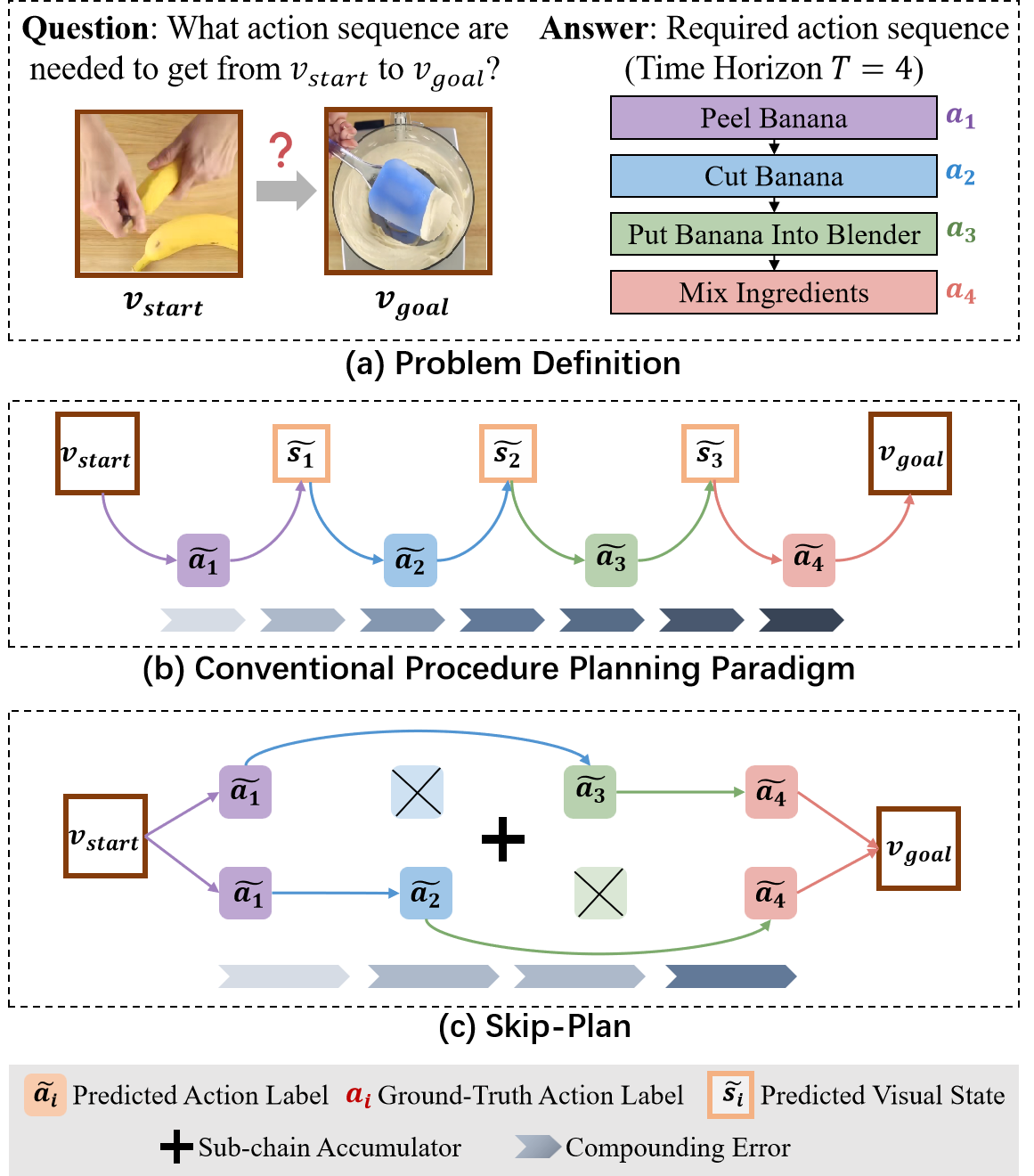
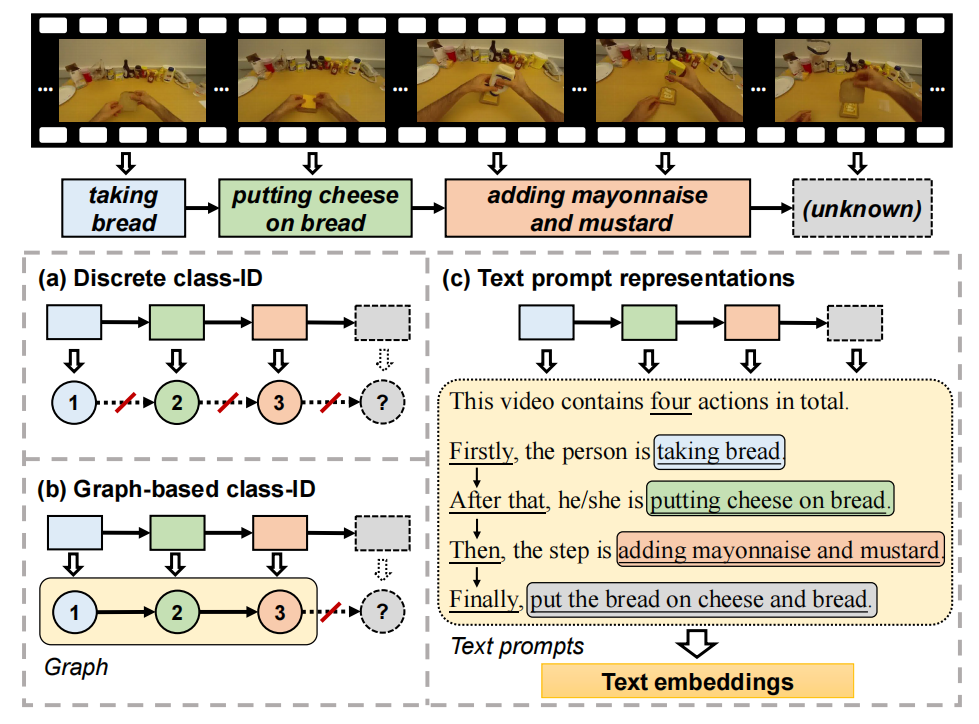
Skip-Plan: Procedure Planning in Instructional Videos via Condensed Action Space Learning
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. We propose Skip-Plan, a condensed action space learning method for procedure planning in instructional videos. we abstract the procedure planning problem as a mathematical chain model. |
|
Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. We propose a prompt-based framework, Bridge-Prompt (Br-Prompt), to model the semantics across adjacent actions, so that it simultaneously exploits both out-of-context and contextual information from a series of ordinal actions in instructional videos. |
|
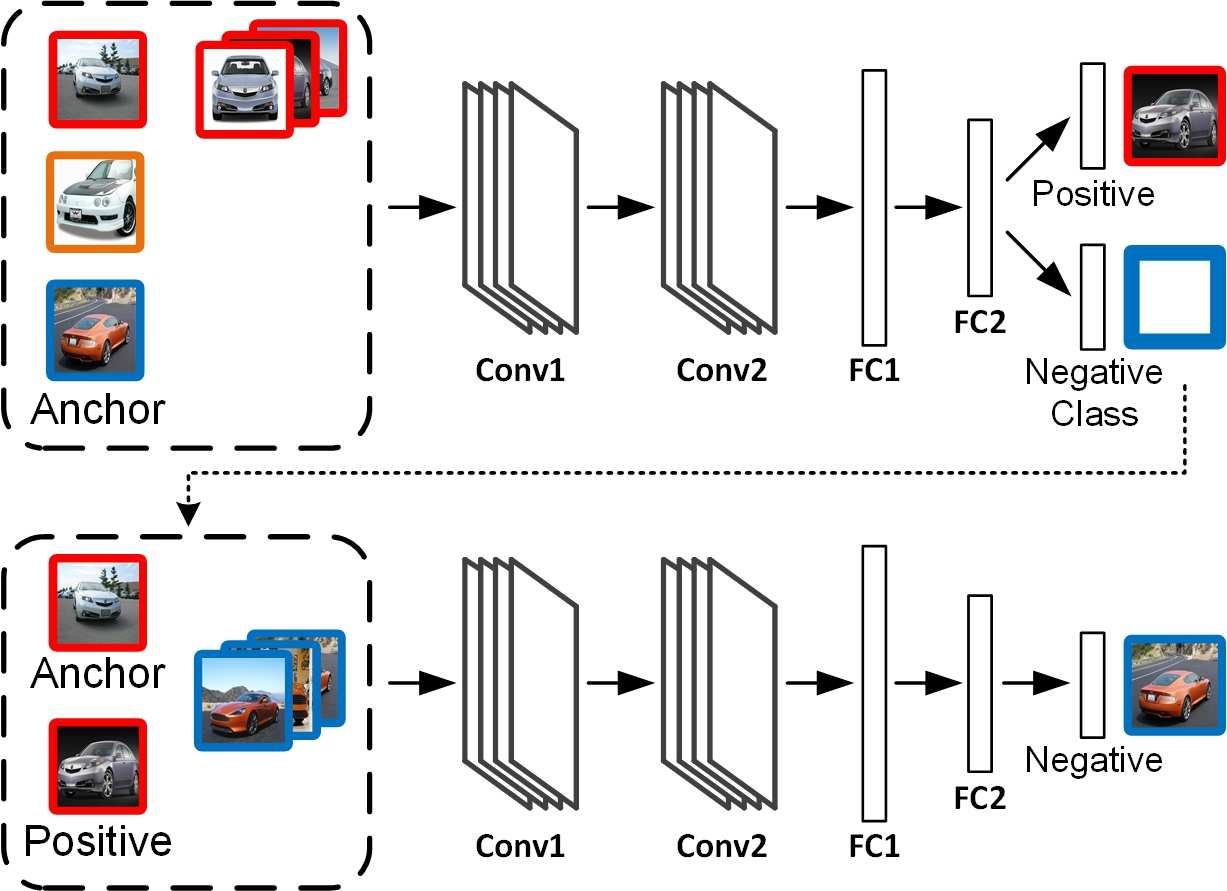
Deep Embedding Learning with Discriminative Sampling Policy
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. We propose a deep embedding with discriminative sampling policy (DE-DSP) learning framework by simultaneously training two models: a deep sampler network that learns effective sampling strategies, and a feature embedding that maps samples to the feature space. |
|
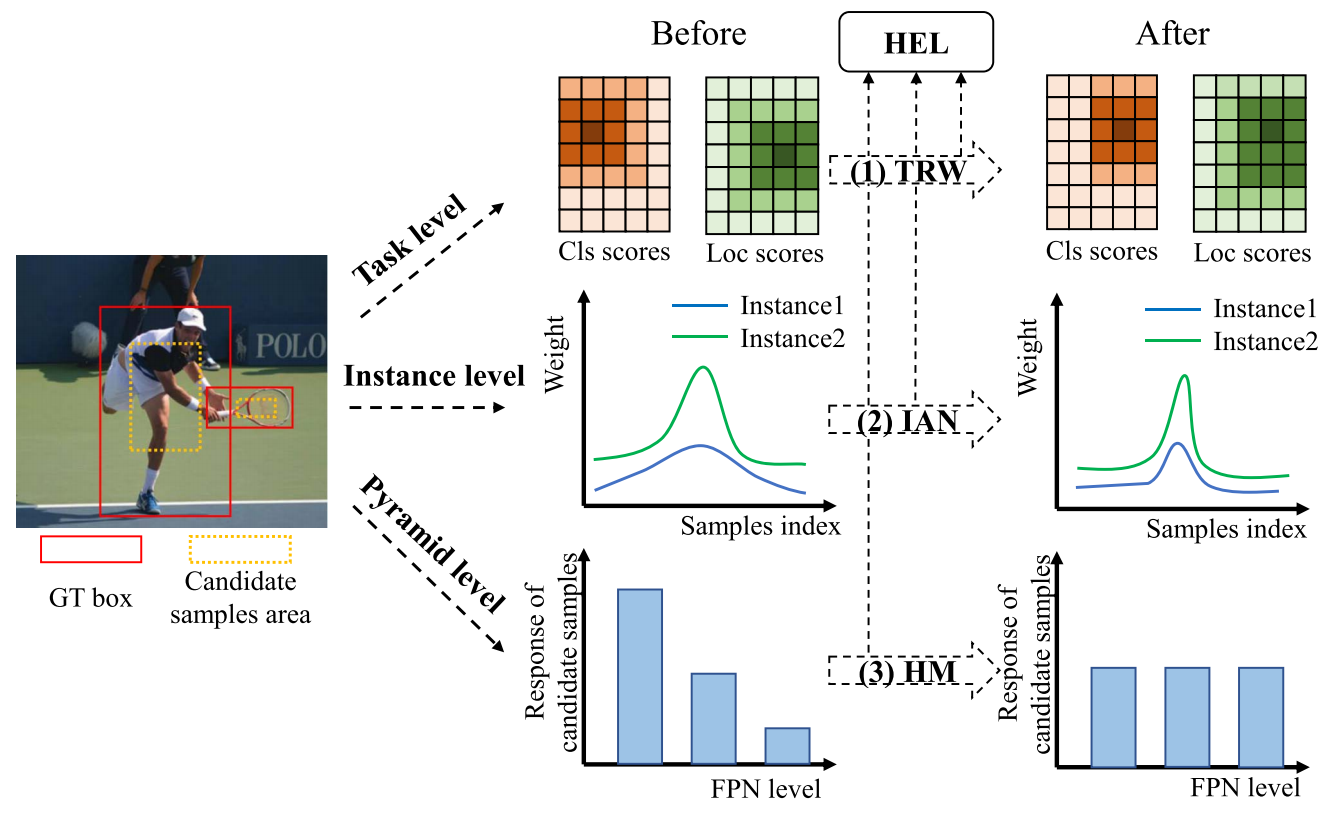
Sample Weighting with Hierarchical Equalization Loss for Dense Object Detection
IEEE Transactions on Multimedia (TMM), 2024. We propose a hierarchical equalization loss (HEL) by reconsidering the underlying factors affecting sample weights. |
|
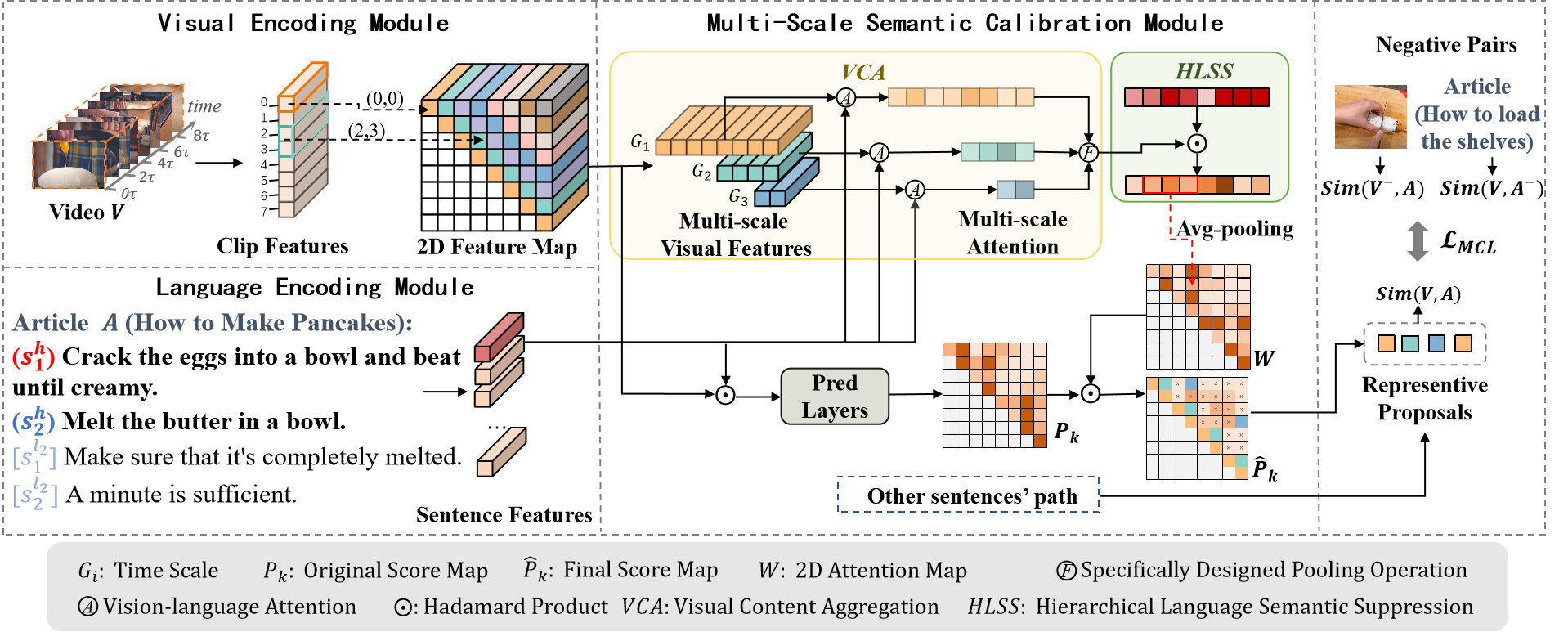
Learning Multi-Scale Video-Text Correspondence for Weakly Supervised Temporal Article Grounding
AAAI Conference on Artificial Intelligence(AAAI), 2024. We propose a Multi-Scale Video-Text Correspondence Learning (MVTCL) framework, which enhances the grounding performance in complex scenes by modeling multi-scale semantic correspondence both within and between modalities. |
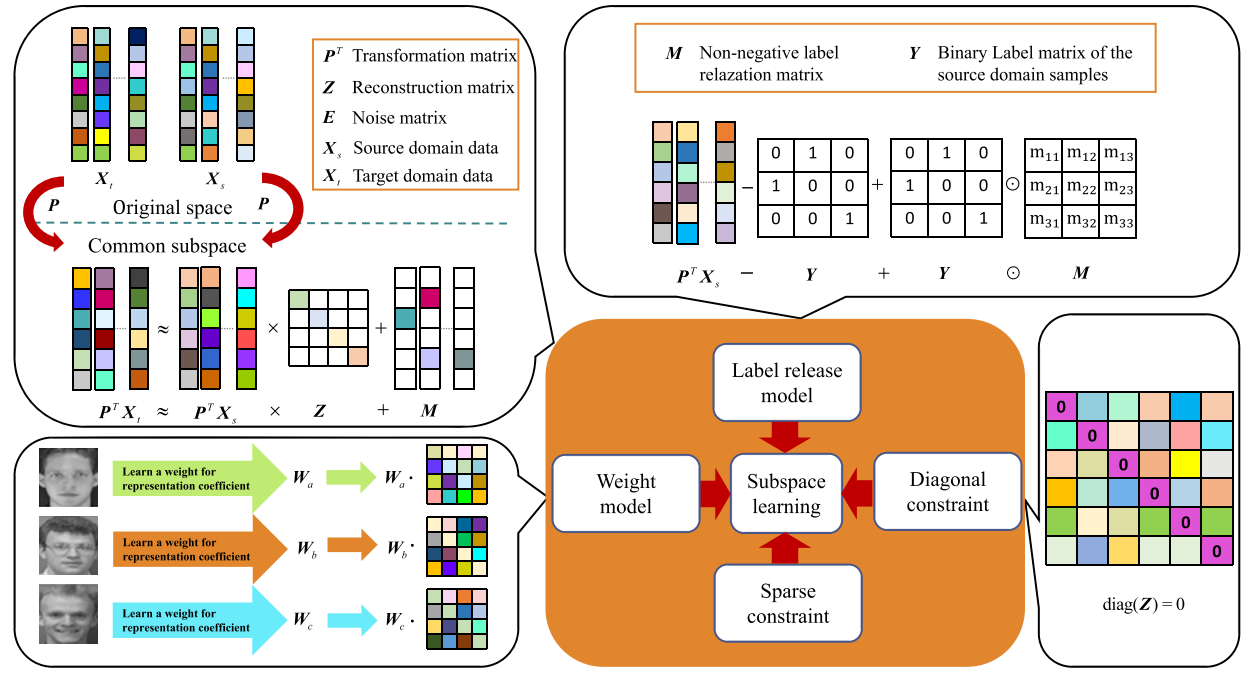
|
Transfer subspace learning via label release and contribution degree distinction
Information Sciences, 2023. We propose a Label Release and Contribution Degree Distinction (LRCDD)-based transfer subspace learning strategy to enhance recognition performance to solve these problems. |
Academic Services
|